
Stable Diffusion là một trong những công cụ AI tạo ảnh nổi bật nhất hiện nay, mang lại khả năng biến ý tưởng từ văn bản thành hình ảnh độc đáo. Với công nghệ tiên tiến, Stable Diffusion đang trở thành lựa chọn hàng đầu cho những người làm sáng tạo, từ quảng bá nhà hàng đến thiết kế nội dung studio. Vậy Stable Diffusion là gì, hoạt động ra sao và làm sao để tận dụng công cụ này hiệu quả?
Nội dung:
Stable Diffusion là gì?
Stable Diffusion (hay còn gọi tắt là SD) là một mô hình trí tuệ nhân tạo dựa trên công nghệ khuếch tán (diffusion model), đây không phải là một phần mềm mà là một phương pháp sử dụng AI để tạo ảnh được phát triển bởi Stability AI.
Stability.ai phát hành mã nguồn và dữ liệu mô hình cơ sở (model base) miễn phí, cho phép người dùng huấn luyện thêm từ dữ liệu này. Nó cho phép người dùng tạo hình ảnh từ mô tả văn bản, mang lại hiệu quả vượt trội trong lĩnh vực tạo ảnh AI online.
Với mã nguồn mở, Stable Diffusion còn cho phép người dùng tùy chỉnh theo nhu cầu riêng. Điều này khiến nó trở thành công cụ lý tưởng cho những nhà sáng tạo nội dung chuyên nghiệp.
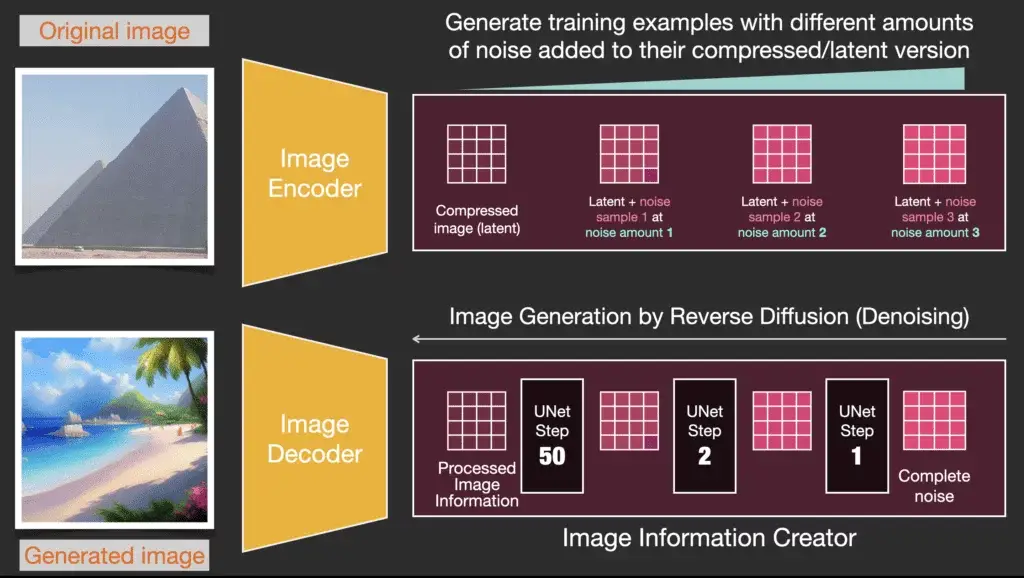
Một số thuật ngữ, khái niệm cơ bản cần biết khi sử dụng Stable Diffusion
Prompt: Là phần text (câu lệnh) mà người dùng nhập yêu cầu hình ảnh tương ứng. Prompt này sẽ được giải mã bằng một bộ trình đọc trong model là CLIP giải mã thành định dạng mà model có thể hiểu được. Mỗi phiên bản Stable Diffusion sẽ có các bộ giải mã khác nhau, vì vậy độ thông minh và hiểu câu lệnh của mỗi phiên bản sẽ có sự khác nhau. Mỗi checkpoint và mỗi phiên bản sẽ có sự hoạt động khác nhau. Một vài website để tham khảo prompt: XLStyle | SD15 Style | Freeflo | NovelAI Tag Experiments
Checkpoint: Là phần model chính giữ vai trò côt lõi cho mọi quá trình hoạt động của Stable Diffusion. Mỗi checkpoint luôn có 2 thành phần chính TextEncoder và Unet, hay có thể nói là phần chữ và phần hình. Hiện nay các checkpoint được chia sẻ ở rất nhiều nguồn khác nhau, phổ biến nhất là CivitAI
Sampler: Sau khi prompt được giải mã thành các thông tin ( textEncoder ) tương ứng. Quá trình UNET sẽ được tiến hành để chuyển đổi thông tin text tương ứng thành hình ảnh. Các hình ảnh sau quá trình UNET sẽ liên tục được gửi lặp lại n lần (steps) thêm chi tiết và hoàn thiện. Quá trình này sẽ lặp lại bằng nhiều phương pháp khác nhau, các phương pháp này gọi là các phương pháp lấy lẫu – Sampler. Thông tin đầy đủ tại đây
VAE (Variational autoencoder): Sau n steps thì quá trình lấy mẫu hoàn tất, khi này chúng ta nhận được hình ảnh dạng Latent. Để hoàn thiện bức ảnh trở về định dạng bình thường với đầy đủ thông tin, một quá trình decoder được thực hiện. Quá trình này yêu cầu một loại model thành phần để có thể hoạt động, chúng ta gọi nó là VAE. Trong trường hợp tác vụ img-img, VAE sẽ làm nhiệm vụ encoder ảnh đầu vào từ định dạng thông thường sang định dạng latent và đưa vào quá trình UNET.
Hiện nay đã số các checkpoint đã được nhúng VAE sẵn, tuy nhiên trường có những trường hợp thiếu VAE, phổ biến là ở các phiên bản v1.5, chúng ta có thể tải thêm VAE tại đây
Stable Diffusion hoạt động như thế nào?
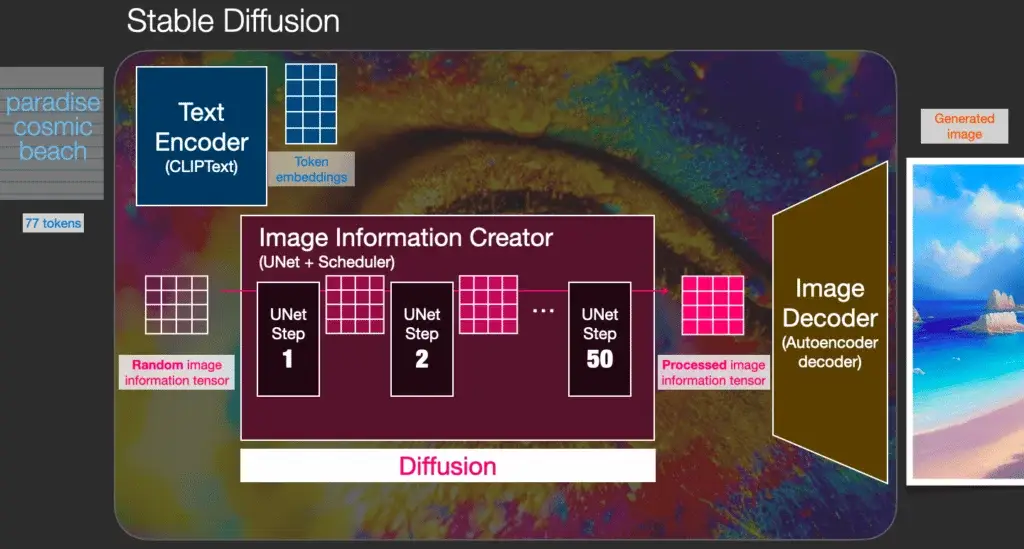
Stable Diffusion vận hành dựa trên quá trình “khuếch tán ngược”. Ban đầu, mô hình học cách thêm nhiễu vào hình ảnh gốc và sau đó đảo ngược quá trình để tái tạo lại hình ảnh từ tiếng ồn. Khi bạn nhập mô tả văn bản, mô hình sẽ sử dụng thông tin này để dẫn dắt quá trình tạo ảnh từ một chuỗi nhiễu ban đầu. Nhờ vào mạng lưới thần kinh nhân tạo và dữ liệu huấn luyện khổng lồ, Stable Diffusion có khả năng hiểu và chuyển đổi ý tưởng trong mô tả thành hình ảnh sát với yêu cầu, từ cảnh quan thiên nhiên đến các phong cách nghệ thuật phức tạp.
Stable Diffusion hoạt động dựa trên việc chuyển đổi thông tin văn bản thành hình ảnh:
- Nhập Prompt: Người dùng nhập yêu cầu hình ảnh bằng văn bản (prompt)
- Giải mã Prompt: Prompt được giải mã thành dạng mà mô hình AI có thể hiểu được bởi bộ giải mã CLIP trong mô hình
- Chuyển đổi Text thành hình ảnh: Quá trình UNET chuyển đổi thông tin văn bản đã được giải mã thành hình ảnh. Hình ảnh được tạo lặp đi lặp lại nhiều lần (steps) để thêm chi tiết và hoàn thiện.
- Phương pháp lấy mẫu (Sampler): Quá trình lặp lại sử dụng nhiều phương pháp lấy mẫu (Sampler) khác nhau để tạo ra hình ảnh.
- Bộ giải mã VAE: Sau khi quá trình lấy mẫu hoàn tất, hình ảnh ở dạng Latent được chuyển đổi về định dạng thông thường bằng bộ giải mã VAE
Sử dụng Stable Diffusion như thế nào?
Stable Diffusion có thể được sử dụng thông qua nhiều phần mềm và công cụ giao diện người dùng (GUI) khác nhau. Một số công cụ phổ biến bao gồm:
Automatic1111 (A1111)
Giao diện GUI phổ biến và dễ sử dụng nhất, hỗ trợ nhiều Extension và thường xuyên cập nhật phiên bản mới. Người dùng có thể tải và cài đặt miễn phí trên nhiều nền tảng hoặc sử dụng online qua Google Colab.
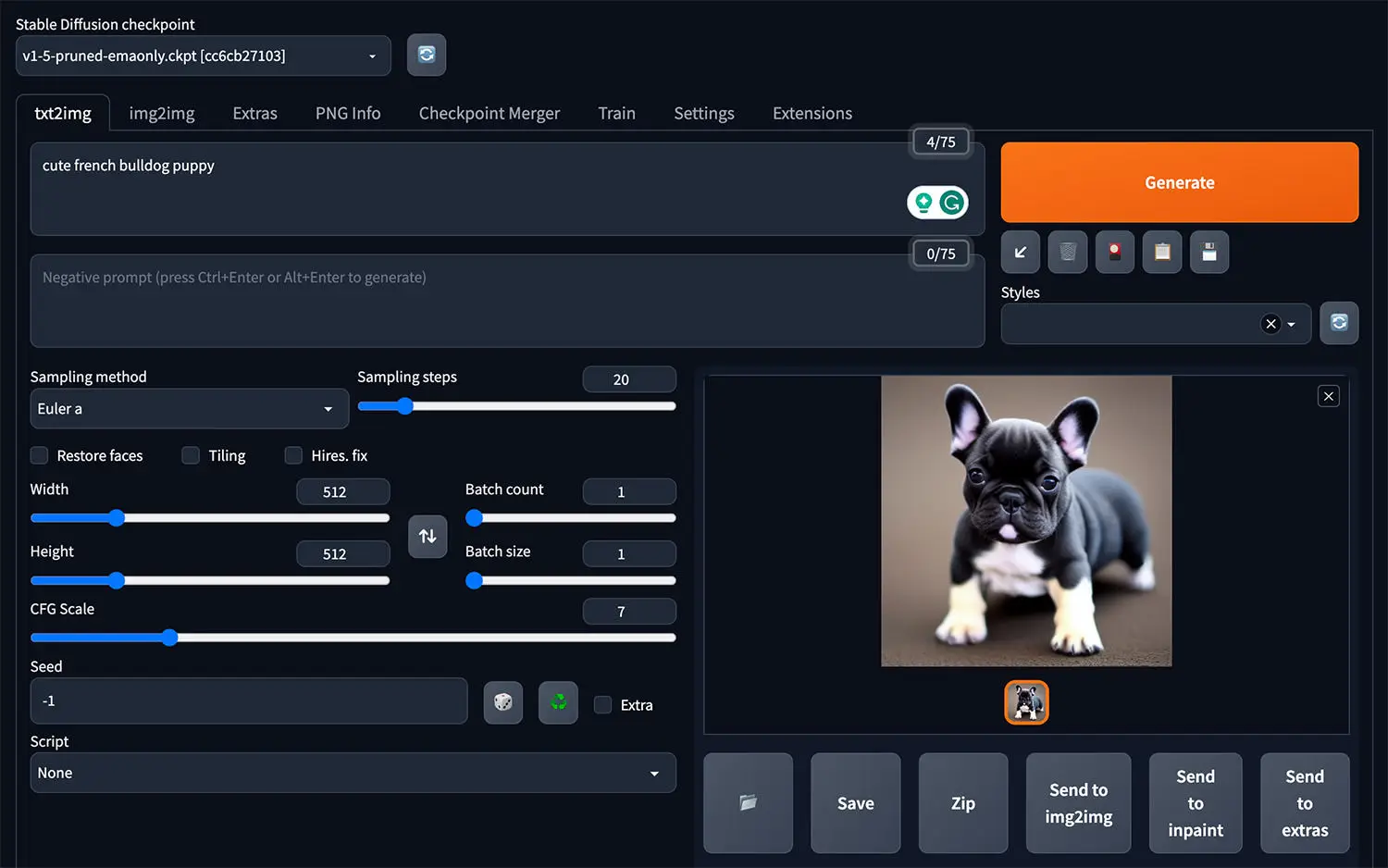
Đây là một giao diện GUI phổ biến và mạnh mẽ và dễ dùng nhất được viết cho Stable Diffusion. A1111 phổ biến đến mức có khi người ta nhầm tưởng Stable Diffusion chính là A1111. Khả năng mạnh mẽ nhất của Automatic1111 đó chính là lượng Extension dồi dào và đa dạng phục vụ gần như mọi yêu cầu của người dùng. A1111 cũng thường xuyên cập nhật các phiên bản để hỗ trợ các phiên bản mới của Stable Diffusion. A1111 có rất nhiều option để người dùng cá nhân hoá sâu các tác vụ cũng như cung cấp các lựa chọn tuỳ biến phần mềm.
ComfyUI
Giao diện theo kiểu workflow – node kéo thả, cho phép người dùng sáng tạo workflow riêng biệt và tối ưu hóa các tác vụ. Hỗ trợ tải và cài đặt miễn phí trên mọi nền tảng hoặc sử dụng online qua Google Colab.
Khác với A1111, ComfyUI tỏ ra khá khó tiếp cận người dùng hơn vì yêu cầu người dùng cần phải nắm chắc nguyên lý vận hành của Stable Diffusion. Cách sử dụng Comfy theo các note kéo thả cũng khá khó tiếp cận với đại đa số người dùng phổ thông. Điểm mạnh nhất của ComfyUI là khả năng cho phép người dùng sáng tạo không giới hạn các workflow phục vụ cho từng nhu cầu riêng biệt, tối ưu hoá tất cả các tác vụ trong 1 click. Người dùng có thể chia sẻ các wofkflow một cách đơn giản cũng như xuất API cho bất kỳ workflow nào.
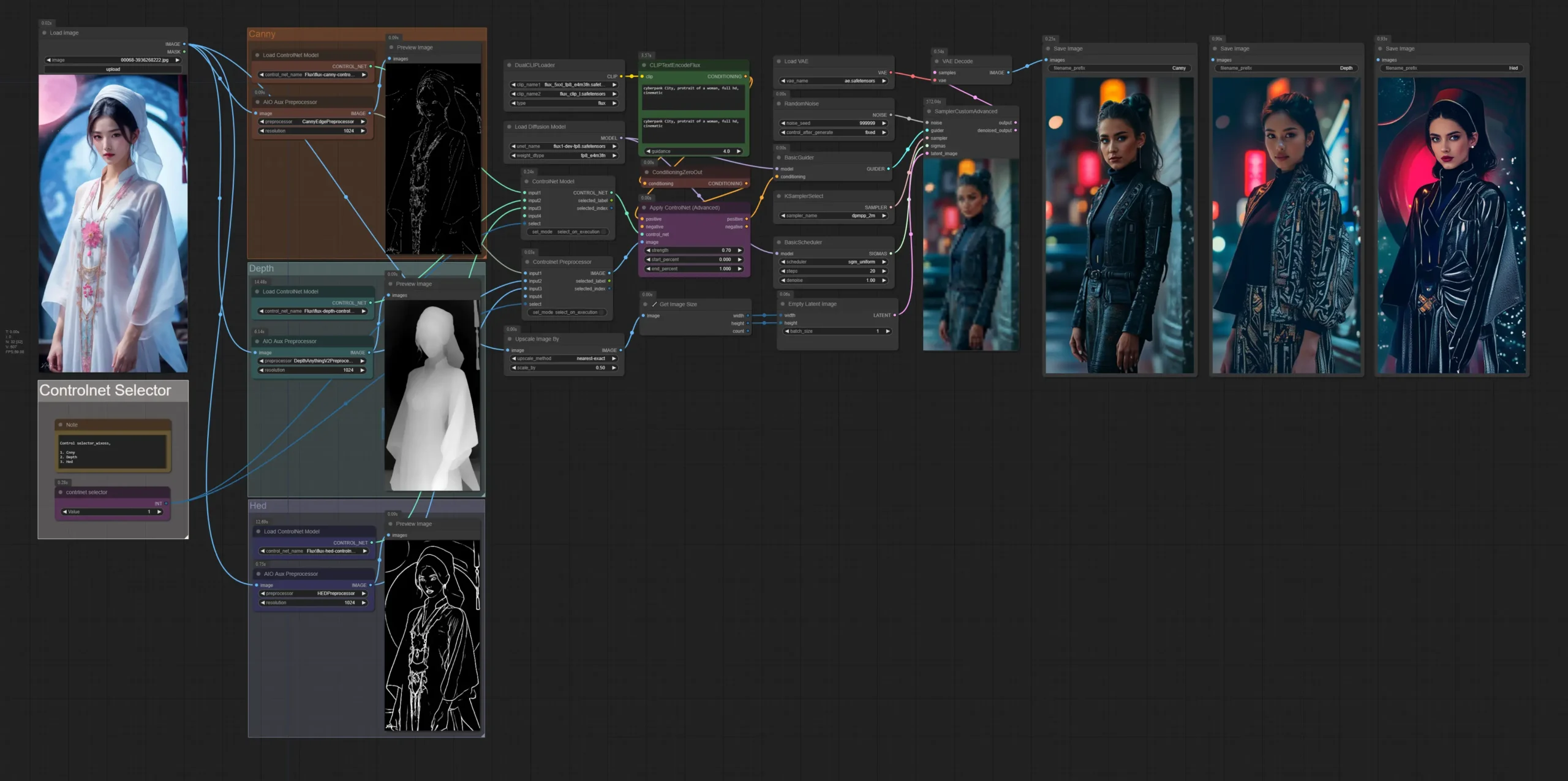
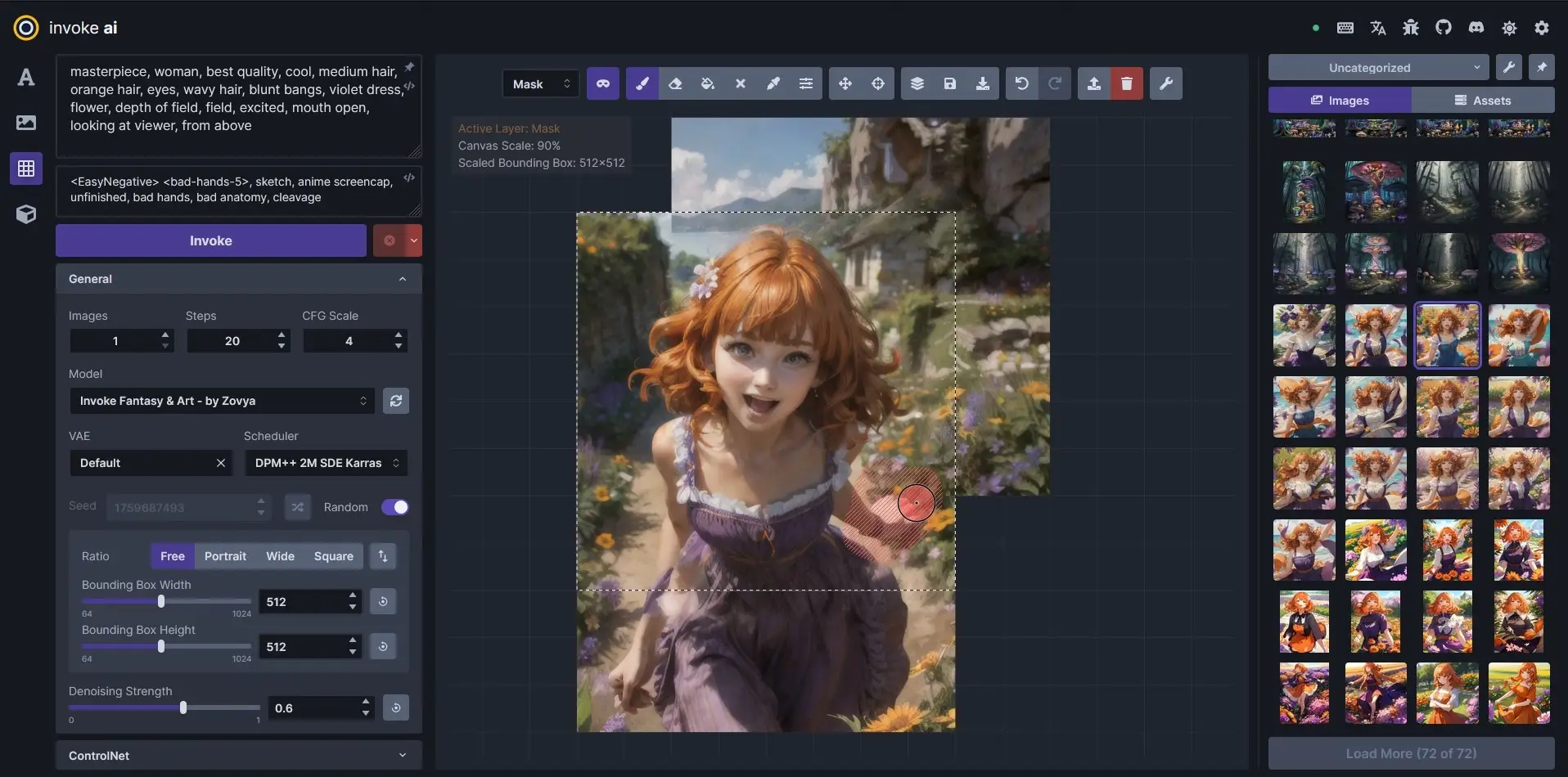
InvokerAI
Kết hợp ưu điểm của A1111 và ComfyUI, giao diện hiện đại và cho phép quản lý ảnh, thư viện nhất quán. Tuy nhiên, InvokerAI không cho phép phát triển extension mở và cập nhật công nghệ mới chậm.
InvokerAI có thể nói là sự kết hợp của Automatic1111 và ComfyUI kèm với đó là sự nâng cấp đang kể về giao diện hiện đại hơn. Hiện tại InvokerAI có thể hoạt động trên cả 2 loại generate ảnh là workflow note kéo thả và generate ảnh mặc định theo giao diện có sẵn. Invoker khá chú trọng tới trải nghiệm người dùng khi cho phép quản lý ảnh và thư viện tài nguyên một cách nhất quán ngay trên giao diện sử dụng. Tuy nhiên Invoker lại không cho phép phát triển các extension mở, các update công nghệ mới khá chậm dẫn đến việc khá kén người dùng phổ thông.
Ngoài ra khi sử dụng Invoker AI, các cú pháp về prompt cũng được viết khác hoàn toàn cho với ComfyUI và Automatic cũng là một điểm trừ khiến cho người dùng khó tiếp cận.
Fooocus
Phần mềm được phát triển riêng cho SDXL, tối ưu hóa cho người dùng dễ tiếp cận và sử dụng. Dễ dàng cài đặt và sử dụng online – offline trên nhiều nền tảng.
Đây là phần mềm được phát triển riêng để sử dụng các model SDXL. Fooocus được tối ưu hoá một cách đơn giản nhất cho người dùng có thể tiếp cận và sử dụng.Cũng giống như Automatic1111, Fooocus sử dụng giao diện Gradio vì vậy rất dễ cài đặt và sử dụng online – offline trên các nền tảng, host khác nhau.
Làm sao để sử dụng Stable Diffusion mà không cần cài đặt trên máy tính?
Nếu bạn muốn sử dụng Stable Diffusion mà không cần cài đặt trên máy tính, các nền tảng trực tuyến là giải pháp hoàn hảo. Những nền tảng này giúp bạn tạo ảnh nhanh chóng, tiện lợi và không đòi hỏi kiến thức kỹ thuật.
Các web – host dịch vụ online
Hiện tại có rất nhiều các nền tảng và dịch vụ hỗ trợ cài đặt và sử dụng Stable Diffusion, dưới đây là một số nền tảng phổ biến và dễ tiếp cận nhất đối với người dùng:
- Google Colab: Nền tảng của google, dễ cài đặt và sử dụng nhất. Điểm mạnh nhất của colab là khả năng kết nối và động bộ hoá với drive cá nhân cũng như là drive của các tài khoản khác nhau. Tuy nhiên hiện tại Colab đang hạn chế các hoạt động generate ảnh bằng Stable Diffusion trên tài khoản miễn phí.
- Kaggle: Nền tảng tương tự với Google Colab, hoạt động theo phương thức Jupyter Note
- Runpod: Nền tảng cho thuê GPU / máy chủ (Khá đắt)
Các nền tảng WebUI online
Shakker AI:
Shakker AI là một nền tảng trực tuyến hỗ trợ tạo hình ảnh bằng công nghệ AI, tương tự như Stable Diffusion. Đây là một công cụ tiện lợi dành cho những người muốn tạo hình ảnh độc đáo mà không cần cài đặt phần mềm phức tạp. Shakker AI tập trung vào việc cung cấp trải nghiệm đơn giản và nhanh chóng, phù hợp cho cả người dùng cá nhân và doanh nghiệp.

- Truy cập: Shakker AI
- Đăng ký tài khoản và nạp tín dụng (có gói miễn phí).
- Chọn model có sẵn phù hợp với nhu cầu sử dụng.
- Nhập mô tả (prompt) và tùy chỉnh các tham số như kích thước ảnh, số bước xử lý.
- Hướng dẫn sử dụng Shakker AI chi tiết.
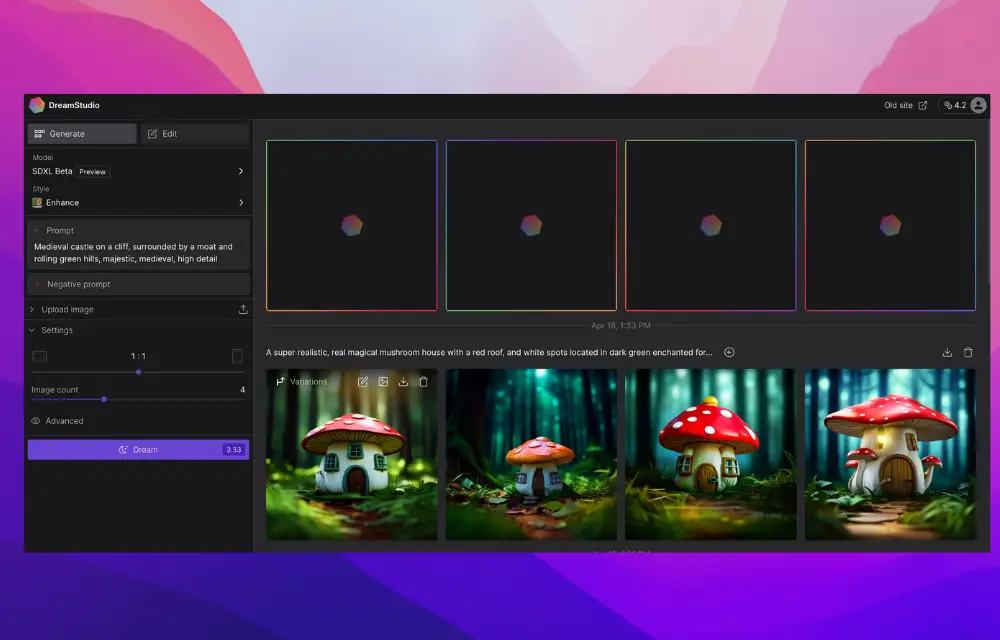
DreamStudio:
DreamStudio là công cụ trực tuyến chính thức của Stability AI. Nó cung cấp giao diện thân thiện để tạo hình ảnh từ mô tả văn bản.
- Truy cập: DreamStudio
- Đăng ký tài khoản và nạp tín dụng (có gói miễn phí).
- Nhập mô tả (prompt) và tùy chỉnh các tham số như kích thước ảnh, số bước xử lý.
Một số nền tảng khác:
- SDVN WebUI: Được phát triển bởi cộng đồng Stable Diffusion Việt Nam, cung cấp các phiên bản WebUI khác nhau như Automatic1111, ComfyUI, InvokerAI,…
- Kaikun AI: Nền tảng của Việt Nam cho phép sử dụng Automatic1111 trực tiếp.
- Tensord Art, CivitAI, SeaArt: Cung cấp dịch vụ tạo ảnh bằng Stable Diffusion với nhiều tính năng và tùy chọn.
Có nhiều cách để sử dụng Stable Diffusion mà không cần cài đặt trực tiếp trên máy tính. Hãy lựa chọn phương pháp phù hợp với nhu cầu và khả năng của bạn.
Làm sao để Stable Diffusion tạo ảnh như ý?

Để tạo ra những hình ảnh đẹp mắt và đúng ý tưởng, bạn cần chú ý đến chất lượng mô tả văn bản (prompt). Một số mẹo giúp bạn tối ưu kết quả khi sử dụng AI tạo ảnh này:
- Chi tiết và rõ ràng: Hãy cung cấp mô tả prompt cụ thể về chủ đề, nội dung, phong cách, màu sắc hoặc ánh sáng. Ví dụ: “Một nhà hàng phong cách cổ điển, ánh sáng vàng ấm áp, có bàn ăn với hoa tươi và rượu vang đỏ.”
- Sử dụng từ khóa chính xác: Nếu muốn hình ảnh mang phong cách nghệ thuật, hãy đề cập đến các chi tiết như “tranh sơn dầu” hoặc “phong cách cyberpunk.”
- Negative Prompts: Sử dụng negative prompts để loại trừ các yếu tố không mong muốn khỏi hình ảnh.
- Điều chỉnh thông số: Thay đổi các thông số như số bước lặp (steps), phương pháp lấy mẫu (sampler), …
- LoRA (Low-Rank Adaptation): Sử dụng LoRA để thêm các chi tiết hoặc phong cách cụ thể vào mô hình.
- Embedding: Sử dụng embedding để thêm các khái niệm mới vào mô hình.
- ControlNet: Sử dụng ControlNet để kiểm soát mô hình bằng hình ảnh thay vì văn bản.
- Thử nghiệm và điều chỉnh: Kết quả tạo ảnh đôi khi cần điều chỉnh tham số như kích thước, độ phân giải, hoặc số bước xử lý để đạt được hình ảnh mong muốn.
Lời khuyên:
- Nên bắt đầu bằng việc sử dụng prompt đơn giản và dần dần thêm các chi tiết khi đã quen với cách hoạt động của mô hình.
- Tham khảo các ví dụ prompt và hình ảnh từ cộng đồng Stable Diffusion để học hỏi kinh nghiệm.
- Luyện tập thường xuyên để nâng cao kỹ năng sử dụng Stable Diffusion.
Stable Diffusion không chỉ mạnh mẽ trong việc tạo ảnh bằng AI mà còn linh hoạt cho nhiều ứng dụng. Từ việc quảng bá nhà hàng với hình ảnh độc đáo đến thiết kế poster cho studio, công cụ này đang thay đổi cách chúng ta làm sáng tạo.
Tóm lại, với Stable Diffusion, bạn không cần phải là một chuyên gia đồ họa để có được hình ảnh đẹp. Chỉ cần một ý tưởng rõ ràng và mô tả chính xác, công cụ này sẽ giúp bạn hiện thực hóa mọi ý tưởng sáng tạo. Hãy bắt đầu khám phá sức mạnh của AI trong tạo hình ảnh bằng AI để nâng tầm công việc của bạn ngay hôm nay!
Bài viết liên quan
20+ Cách dùng NotebookLM hiệu quả giúp bạn grow-up
Nano Banana Pro có update gì? Có điểm nổi bật gì với bản cũ?
Prompt Gemini Tạo Ảnh Quảng Cáo Đồ Uống
Qwen AI có tính năng gì? Thông minh hơn ChatGPT không?
Tổng hợp Trend Prompt tạo ảnh Gemini AI mới nhất
Tổng hợp cách sử dụng Nano Banana tạo ảnh mới nhất